
起因
在研发环境中由于 ElasticSearch 数据被清理,在重建数据的过程中,发现不能够在一个索引下建立多个类型,测试样例和报错如下:
1 | curl -X PUT \ |
后来经过了解发现环境上的 ElaticSearch 版本已经从 5.5.1 升级到了 6.2.3 的版本,而 6.x 版本在 mapping type 上存在了 break changing,早期升级的过程中对于现有的数据进行了自动迁移,不存在问题,但是对于新创建的索引却进行了限制,因此查询了 EleasticSearch 相关的文档并记录下来,以备后续的查找。
话说:Elasticsearch 每个大版本之间的 break changing,对于研发来说的确是个让人头痛的问题,尤其这这种基础的结构。从索引到类型的种种合合分分,用前生今世来形容再贴切不过了, 7.x 版本中类型(Type)的概念将退居二线。
背景知识
一般情况下 ElasticSearch 中的概念都可以和 SQL 关系型数据库进行对应,对应起来也非常方便与大家的理解,简单的对应关系如下:
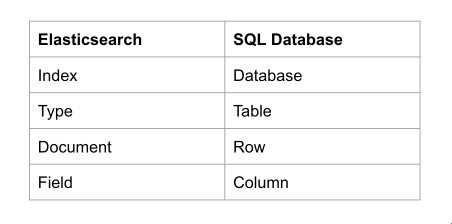
本文的图片主要来自:Federico Panini 的 Elasticsearch 6.0 Removal of mapping types
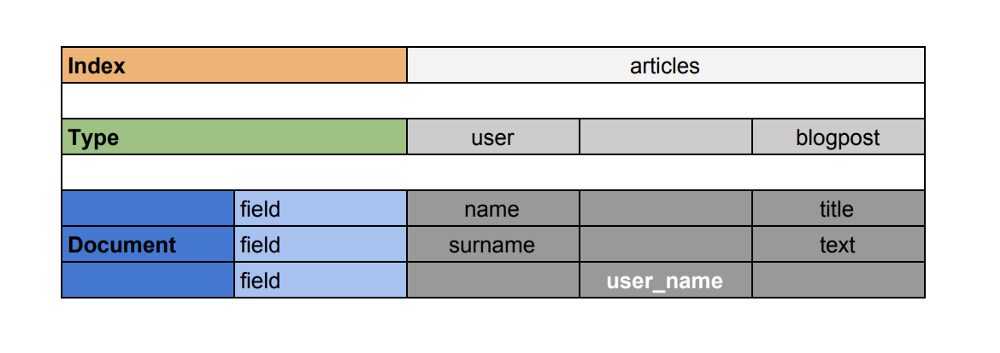
对应上虽然方便了比较和理解,但是 Type 与 Table 的确有很大的不同,关于同一个索引下的多个类型的关系,下图表示的非常清晰:
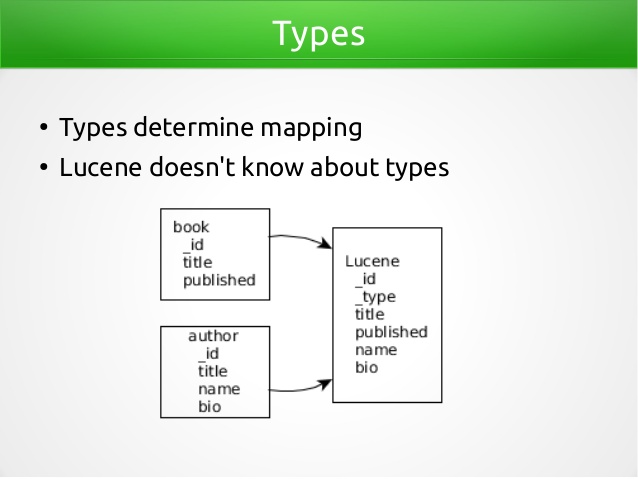
图中的索引 artical 中的两种类型 user 与 blogpost 公有字段 user_name,Lucene 底层没有多类型的概念。
或者参考图:
索引 Index
单词对应:
索引 index 分片 shard 类型 Type 索引集 indices index的复数方式
索引存储在一组分片中,这些分片本身就是 Lucene 索引集。 这已经让您瞥见了始终使用新索引的限制:Lucene索引集在磁盘空间,内存使用情况和使用的文件描述符方面具有较小但固定的开销。 出于这个原因,一个单一的大型索引比几个小型索引更有效率:Lucene 索引集的固定成本在许多文件中被更好地分摊。
另一个重要因素是您计划如何搜索数据。 当每个分片独立搜索时,Elasticsearch 最终需要合并来自所有搜索到的分片的结果。 例如,如果您搜索 10 个索引,每个索引有 5 个分片,协调搜索请求执行的节点将需要合并 5x10 = 50 个分片结果。 在这里,您还需要小心:如果有太多的分片结果要合并和/或如果您运行产生大分片响应的大量请求(当使用聚合的时候这可能很容易发生),合并所有这些分片结果的任务可能会变为 非常耗费资源,无论是CPU 还是内存。 这又会提倡减少索引集。
类型 Type
这是类型帮助的地方:类型是将多种类型的数据存储在相同索引中的一种便捷方式,为了保持上面讲述的原因而降低索引总数。 在实现方面,它通过在搜索特定类型过滤的文档中添加 “_type” 字段用于进行过滤选择。 类型的一个很好的属性是,与搜索单个类型相比,在相同索引下多个类型的中搜索并不会增加开销:它不会更改需要合并多少个分片结果。
因此类型存在一些限制:
- 同一个索引下的类型中的字段必须保持同样的类型,这是因为同一个索引下的类型在底层保存是共享的。
- 在某个类型中的字段,在不存在该字段的其他类型中,仍然需要占据资源。这是因为 Lucene 的索引集不喜欢稀疏性的问题,主要是考虑反向索引在查询中的效率。也就说说在文档中即使相关的字段不存在,但是在进行底层存储的时候仍然需要占据对应的字节资源。
- Score 的统计是在索引级别的,在同一个类型的中的文档查询中的 Score 可能会被该索引下的其他的类型所影响。
因此说类型的作用可能仅仅会在索引中类型的 Mapping 比较相似的时候比较有作用。但是,事实是在文档中的不存在的字段仍然会占据资源的事实,在数据保存在单独的索引中可能会更加严重。
至于是选择每个索引一个类型,还是每个索引多个类型,取决于我们的使用场景和硬件资源。例如如果我们将五个类型放入了一个索引中,我们也可以创建一个5个索引每个创建一个主分片。
以下问题可以帮助我们选择:
- 如果使用了 parent/child 模型?如果是,那么只能通过相同索引下的两种类型来实现
- 如果文档具备相类似的 mapping?如果不是,则采用不同的索引
- 每种类型是否还有很多文档,如果是的话 Lucene 可以很容易处理这种问题,可以放心使用索引集,设置比默认值 5 更小的分区
- 否则你可以考虑将不同类型的文档放入到相同的索引中,甚至是同一种类型中
类型映射
类型映射类似于数据表的 Schema, 提供了在索引中数据如何被保存和索引。
移除映射类型(mapping type)
同一索引中的多个类型实际上不应该被经常使用,并且类型的少数用例之一是父子关系。

从 ElasticSearch 的第一个版本开始,每个文档都会被保存到一个单独的索引中,并指定一个单独的映射类型。具体讨论参见 Remove support for types?
映射类型用来表示一个文档或实体的类型。比如我们在索引 twiiter 中可能含有 user 和 tweet两个类型。每个映射类型都尅包含自己的低端,因此 user类型中可以包含 full_name字段,tweet类型中可以包含 context字段和 user_name 字段。
每个文档中中都默认包含一个元字段 _type 包含了类型的名字,搜索的时候可以在 url 地址中输入一个或者多个类型名称,比如我们可以同时在 user和tweet两种类型下进行搜索:
1 | GET twitter/user,tweet/_search |
_type 字段会和文档的 _id 一起生成一个 _uid 字段,因此在同一个索引下的不同类型的文档的 _id 可以具有相同的值。
映射类型可以用来在不同的文档中建立父子关系, 比如文档类型 question 可能是 answer 的父文档。
为什么要移除映射类型
一开始,大家都比较喜欢将索引等价于数据库,而类型等价于表,其实这种讲法存在着很大的误导性。因为在 SQL 数据库中,表是各自完全独立的,一个表中的列与另一个表中的相同名称的列没有关系。但是在映射类型中却不是完全独立,要求在不同映射类型中的相同字段名称的具备的类型须完全一样。映射类型缺点1: 同一个索引下的类型中的字段必须保持同样的类型,这是因为同一个索引下的类型在底层保存是共享的。 这样对于不同类型中相同名称的字段进行了限制,比如在同一个索引下 deleted 在一个类型中可能需要保存为 data 类型,而在另外一个类型中需要保存为 boolean 类型。
最重要的是,存储同一索引中具有很少或没有共同字段的不同实体会导致稀疏数据并干扰 Lucene 高效压缩文档的能力。参见:LUCENE-6863
For both NUMERIC fields and ordinals of SORTED fields, we store data in a dense way. As a consequence, if you have only 1000 documents out of 1B that have a value, and 8 bits are required to store those 1000 numbers, we will not require 1KB of storage, but 1GB.
I suspect this mostly happens in abuse cases, but still it’s a pity that we explode storage requirements. We could try to detect sparsity and compress accordingly.
因此基于此,ElasticSearch 从 6.0 版本开始,将逐渐来达到移除映射类型的功能。
映射类型的替代
一个文档类型一个索引
比如将上例子中的 user 和 tweet 独立成单独的索引。这样的做法有以下好处:
- 数据保存的会更加紧凑,更好利于 Lucene 的压缩技术
- 在全局搜索中的 score 值将会更加准确,因为不在有同索引下的其他文档类型干扰
每个索引需要根据其包含的文档数目来进行合理地规划,比如可以将 user 索引的主分区所致的数目少一些,而将 tweets 的主分区数目设置的比较大。
自定义 type 字段
当然,在一个集群中有个主分区数目的限制,你可能不想让少数的文档来浪费一系列的分区。这种情况下,你可以实现自己定义的 type 字段,像以前 _type的机制类似。仍然拿上面 user/tweet` 为例。原来的流程大体如下:
1 | PUT twitter |
通过自定义的 type 则方式如下:
1 | PUT twitter |
需要在上文的 1、2、3、4的地方显示地指定 type 类型。
移除映射类型后的父子模型
由于父子模型是通过一个索引中多个类型来实现的,那么在移除影视类型后,该功能将不再使用。可以使用 join 的字段来进行实现。
移除映射类型的计划
修改这种模型将会是一个比较大的变化,因此 Elasticsearch 也在尽量少影响用户的前提下,做了一些功能的规划:
ElasticSearch 5.6.0
在索引上设置
index.mapping.single_type: true来启用单个类型单个索引,6.0 版本后会进一步增强从 5.6.0 版本开始,使用
join字段来替换 父子关系
Elasticsearch 6.x
- 5.x 创建的索引在 6.x 版中将继续可以使用
- 6.x 中将只允许单个类型单个索引, 比较推荐的类型名字为
_doc, 这样可以让索引的API具备相同的路径PUT {index}/_doc/{id}和POST {index}/_doc _type字段名称将不再与_id字段合并生成_uid字段,_uid字段将作为_id的别名。- 新的索引将不再支持父子关系,应该采用
join字段类进行替代 _default映射类型将不推荐使用
Elasticsearch 7.x
URL 中的
type参数做变为可选。例如,所以文档将不再需要type。指定 id 的 URL 将变为PUT {index}/_doc/{id}, 自动生成 id 的 URL 为:POST {index}/_docGET | PUT _mappingAPI 支持查询字符串参数(include_type_name),该参数指示主体是否应包含类型名称。 它默认为 true, 7.x 没有显式类型的索引将使用虚拟类型名称_doc。_default映射类型将被移除
Elasticsearch 8.x
参数
type在 URL 中将不再被支持参数
include_type_name默认seize为false
Elasticsearch 9.x
- 参数
include_type_name将被移除
迁移多类型索引到单类型索引
Reindex API 用来将多类型的索引迁移到单类型索引。以下的样例可以运行在 5.6 和 6.x 版本中。在 6.x 版本中不需要设置参数 index.mapping.single_type, 因为已经是默认值。
单类型索引
1 | PUT users |
定制 type 字段
添加自定义的 type 字段,设置成原来 _type 的值。同时,将类型添加到 _id字段,以防止不同类型的文档包含了相同的 id
1 | PUT new_twitter |
参考
- Index vs Type
- Removal of mapping types
- Indices, types, and parent/child: current status and upcoming changes in Elasticsearch
- Data modeling for Elasticsearch
- Elasticsearch 6.0 Removal of mapping types
除特别声明本站文章均属原创(翻译内容除外),如需要转载请事先联系,转载需要注明作者原文链接地址。