
Slice 怪异现象分析实例
原贴地址:https://gocn.io/question/1852
1 | package main |
诡异的现象:如果有行 14 的代码,则行 15 打印的结果为 a b, 否则打印的结果为b b ,本文分析的go版本:
1 | $ go version |
初步分析
首先我们分析在没有行14的情况下,为什么打印的结果是 b b,这个问题相对比较简单,只要熟悉 slice 的实现原理,简单分析一下 append 的实现原理即可得出结论。
slice 结构分析
如果熟悉 slice 的原理可以跳过该章节。
首先对于 slice 结构进行一个简单的了解 结构定义 slice对应的runtime 包的相关源码参见: https://golang.org/src/runtime/slice.go
1 | type slice struct { |

var slice []int 定义的变量内部结构如下:
1 | slice.array = nil |
如果我们声明了一下变量 slice := []int{} 或 slice := make([]int, 0) 的内部结构如下:
1 | slice.array = 0xxxxxxxx // 分配了地址 |
如果使用 make([]byte, 5) 定义的话,结构如下图:
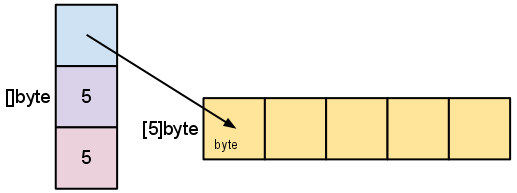
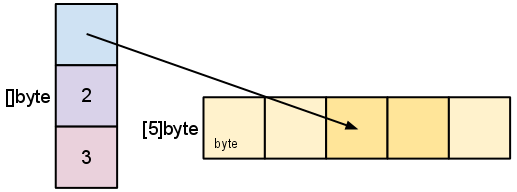
如果使用 s := s[2:4],则结构如下图:
通过分析 slice 的反射de 实现:Go Slices: usage and internals,也能够在程序中进行分析。slice 反射中对应的结构体
1 | // slice 对应的结构体 |
下面的函数可以直接获取 slice 的底层指针:
1 | func bytePointer(b []byte) unsafe.Pointer { |
append 原理实现
Append 的实现伪代码,代码默认已经支持了 slice 为 nil 的情况
1 | func Append(slice, data []byte) []byte { |
append 函数原型如下,其中 T 为通用类型。
1 | func append(s []T, x ...T) []T |
展开分析
为了方便程序分析的,我们在程序中添加打印信息,代码和结果如下:
1 | package main |
运行程序结果如下:
1 | $ go run q.go |
结果运行后 s := []byte("") 初始化以后结构内部如下:
1 | s.len = 0 |
我们分析以下两行代码调用会发生什么:
1 | s1 := append(s, 'a') |
s1 := append(s, 'a') 代码调用分析:
1 | // slice = s data = `a` slice.len = 0 slice.cap = 32 |
s2 := append(s, 'b') 的分析完全一样。
简化 apend 函数的处理路径,在没有进行 slice 重新分配内存情况下,直接进行展开分析:
1 | s1 := append(s, 'a') |
等价于
1 | s1 := copy(s[0:], 'a') |
基于上述分析,能够很好地解释代码输出b b的情况。但是如何避免出现这种类型的情况呢?问题出现在这条语句上
1 | s := []byte("") |
语句执行后 s.len = 0 s.cap = 32,导致了 append 的工作不能够正常工作,那么正常如何使用?只要将 s.len = s.cap = 0 则会导致 slice 在 append 中重新进行分配则可以避免这种情况的发生。
正确的写法应该为:
1 | func main() { |
由此也可以看出一个良好的编程习惯是可以规避很多莫名其妙的问题排查。
深入分析
那么既然 bug 出现在了 s := []byte("")这句话中,那么这条语句为什么会导致 s.cap = 32 呢?这条语句背后隐藏的逻辑是什么呢?
s := []byte("") 等价于以下代码:
1 | // 初始化字符串 |
在go语言中 s := []byte(str) 的底层其实是调用了 stringtoslicebyte 实现的,该函数位于 go 的 runtime包中。
1 | const tmpStringBufSize = 32 |
如果字符串的大小没有超过 32 长度的大小,则默认分配一个 32 长度的 buf,这也是我们上面分析 s.cap = 32 的由来。
到此为止,我们仍然没有分析问题中 fmt.Println(s1, "===", s2) 这句打印注释掉就能够正常工作的原因?那么最终到底是什么样的情况呢?
最终分析
最后我们来启用魔法的开关 fmt.Println(s1, "===", s2), 来进行最后谜底的揭晓:
1 | package main |
1 | $ go run q.go |
1 | $ go run -gcflags '-S -S' q.go |
通过分析发现底层调用的仍然是 runtime.stringtoslicebyte(), 但是行为却发生了变化 s.len = s.cap = 0,很显然由于 fmt.Println(s1, "===", s2) 行的出现导致了 s := []byte("")内存分配的情况发生了变化。
我们可以通过 go build 提供的内存分配工具进行分析:
1 | $ go build -gcflags "-m -m" q.go |
以上输出中的 s1 escapes to heap 和 ([]byte)("") escapes to heap 表明,由于 fmt.Println(s1, "===", s2) 代码的引入导致了变量分配模型的变化。简单点讲就是从栈中逃逸到了堆上。内存逃逸的分析我们会在后面的章节详细介绍。问题到此,大概的思路已经有了,但是我们如何通过代码层面进行验证呢? 通过搜索 go 源码实现调用的函数 runtime.stringtoslicebyte 的地方进行入手。通过搜索发现调用的文件在 cmd/compile/internal/gc/walk.go
1 | case OSTRARRAYBYTE: |
1 | OSTRARRAYBYTE // Type(Left) (Type is []byte, Left is a string) |
上述代码中的 n.Esc == EscNone 条件分析则表明了发生内存逃逸和不发生内存逃逸的情况下,初始化的方式是不同的。 EscNone 的定义:
1 | EscNone // Does not escape to heap, result, or parameters. |
通过以上分析,我们总算找到了魔法的最终谜底。 以上分析的go语言版本基于 1.9.2,不同的go语言的内存分配机制可能不同,具体可以参见我同事更加详细的分析 Go中string转[]byte的陷阱.md
Go 内存管理
Go 语言能够自动进行内存管理,避免了 C 语言中的内存自己管理的麻烦,但是同时对于代码的内存管理和回收细节进行了封装,也潜在增加了系统调试和优化的难度。同时,内存自动管理也是一项非常困难的事情,比如函数的多层调用、闭包调用、结构体或者管道的多次赋值、切片和MAP、CGO调用等多种情况综合下,往往会导致自动管理优化机制失效,退化成原始的管理状态;go 中的内存回收(GC)策略也在不断地优化过程。Golang 从第一个版本以来,GC 一直是大家诟病最多的,但是每一个版本的发布基本都伴随着 GC 的改进。下面列出一些比较重要的改动。
- v1.1 STW
- v1.3 Mark STW, Sweep 并行
- v1.5 三色标记法
- v1.8 hybrid write barrier
预热基础知识:How do I know whether a variable is allocated on the heap or the stack?
逃逸分析-Escape Analysis
更深入和细致的了解建议阅读 William Kennedy 的 4 篇 Post
go 没有像 C 语言那样提供精确的堆与栈分配控制,由于提供了内存自动管理的功能,很大程度上模糊了堆与栈的界限。例如以下代码:
1 | package main |
行 10 中的变量 s = "hello" 尽管声明在了 GetString() 函数内,但是在 main 函数中却仍然能够访问到返回的变量;这种在函数内定义的局部变量,能够突破自身的范围被外部访问的行为称作逃逸,也即通过逃逸将变量分配到堆上,能够跨边界进行数据共享。
Escape Analysis 技术就是为该场景而存在的;通过 Escape Analysis 技术,编译器会在编译阶段对代码做了分析,当发现当前作用域的变量没有跨出函数范围,则会自动分配在 stack 上,反之则分配在 heap 上。 go 的内存回收针对的也是堆上的对象。go 语言中 Escape Analysis还未看到官方 spec 的文档,因此很多特性需要进行代码尝试和分析才能得出结论,而且 go Escape Analysis 的实现还存在很多不完善的地方。
stack allocation is cheap and heap allocation is expensive.
Go 语言逃逸分析实现
更多内存建议阅读 Allocation efficiency in high-performance Go services
2.go
1 | package main |
go build 工具中的 flag -gcflags '-m' 可以用来分析内存逃逸的情况汇总,最多可以提供 4 个 “-m”, m 越多则表示分析的程度越详细,一般情况下我们可以采用两个 m 分析。
1 | $ go build -gcflags '-m -l' 2.go |
上例中的 x escapes to heap 则表明了变量 x 变量逃逸到了堆(heap)上。其中 -l 表示不启用 inline 模式调用,否则会使得分析更加复杂,也可以在函数上方添加注释 //go:noinline禁止函数 inline调用。至于调用 fmt.Println()为什么会导致 x escapes to heap,可以参考 Issue #19720 和 Issue #8618,对于上述 fmt.Println() 的行为我们可以通过以下代码进行简单模拟测试,效果基本一样:
1 | package main |
内存逃逸分析结果如下:
1 | $ go build -gcflags '-m -m -l' 3.go |
逃逸的常见情况分析参见: http://www.agardner.me/golang/garbage/collection/gc/escape/analysis/2015/10/18/go-escape-analysis.html
主要原因如下:变量 x 虽为 int 类型,但是在传递给函数 MyPrintln函数中被转换成 interface{} 类型,因为 interface{} 类型中包含指向数据的地址,因此 x 在传递到函数 MyPrintln过程中进行了一个内存重新分配的过程,由于 pp.arg = a 结构体中的字段赋值的引用,导致了后续变量的逃逸到了堆上。如果将上述 pp.arg = a 注释掉,则不会出现内存逃逸的情况。
导致内存逃逸的情况比较多,有些可能还是官方未能够实现精确的分析逃逸情况的 bug,简单一点来讲就是如果变量的作用域不会扩大并且其行为或者大小能够在编译的时候确定,一般情况下都是分配到栈上,否则就可能发生内存逃逸分配到堆上。
简单总结一下有以下几类情况:
发送指针的指针或值包含了指针到
channel中,由于在编译阶段无法确定其作用域与传递的路径,所以一般都会逃逸到堆上分配。slices中的值是指针的指针或包含指针字段。一个例子是类似[] *string的类型。这总是导致slice的逃逸。即使切片的底层存储数组仍可能位于堆栈上,数据的引用也会转移到堆中。slice由于append操作超出其容量,因此会导致slice重新分配。这种情况下,由于在编译时slice的初始大小的已知情况下,将会在栈上分配。如果slice的底层存储必须基于仅在运行时数据进行扩展,则它将分配在堆上。调用接口类型的方法。接口类型的方法调用是动态调度 - 实际使用的具体实现只能在运行时确定。考虑一个接口类型为
io.Reader的变量 r。对r.Read(b)的调用将导致r的值和字节片b的后续转义并因此分配到堆上。 参考 http://npat-efault.github.io/programming/2016/10/10/escape-analysis-and-interfaces.html尽管能够符合分配到栈的场景,但是其大小不能够在在编译时候确定的情况,也会分配到堆上
关于指针
关于指针的使用多数情况下我们会受一个前提影响:“指针传递过程不涉及到底层数据拷贝,因此效率更高”,而且一般情况下也的确是如此。
但是由于指针的访问是间接寻址,也就是说访问到了指针保存的地址后,还需要根据保存的地址再进行一次访问,才能获取到指针所指向的数据,另外一种情况对于指针在使用的时候还需要进行 nil 情况的判断,以防止 panic 的发生,更重要的是指针所指向的地址多数是保存在堆上,在涉及到内存收回的情况下,指针的存在可能会让程序的性能大打折扣。除此之外由于指针的间接访问,还会导致缓存的优化失效,可以参考 Locality of reference,当前在缓存中拷贝少量数据与指针的访问相比,性能上基本上可以等同。
综上所述,指针的使用也不是没有代价的,需要合理进行使用。
“the garbage collector will skip regions of memory that it can prove will contain no pointers”
简单点讲,如果在堆上分配的结构中指针比较少,回收的机制会比较简单,应该会提升回收的效率,需要通过了解 go 回收算法进行相关测试 。 TODO
关于接口转换
接口实现参见: Go Data Structures: Interfaces Go interfaces: static vs dynamic binding

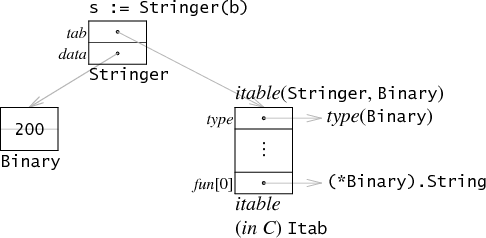
上图展示了一个 Binary 对象转换成一个 Stringer 接口后的数据结构。检查类型是否匹配 s.tab->type 即可。
go 语言中的 interface 接口,在编译时候的时候会进行隐式转换的静态检查,但是显示的 interface 到 interface 的转换可以在运行时查询方法集,动态检测比如:
1 | type Stringer interface { |
关于 Itab 结构的计算,由于(interface、type)对的不确定性,go 编译器或者链接器不可能在编译的时候计算两者的对应关系,而且即使能够计算出来也可能是绝大多数的对应关系在实际中不适用;因此 go 编译器会在编译的过程中对于 interface 和 type 中的方法生成一个相关的描述结构,分别记录 interface 和 type 各自对应的方法集合,go 语言会在 type 实际的动态转换成 interface 过程中,将 interafce 中定义的方法在 type 中一一进行对比查找,并完善 Itab 结构,并将 Itab 结构进行缓存提升性能。
综上所述,go 中的接口类型的方法调用是动态调度,因此不能够在编译阶段确定,所有类型结构转换成接口的过程会涉及到内存逃逸的情况发生。如果对于性能要求比较高且访问频次比较高的函数调用,应该尽量避免使用接口类型。
以下样例参考:http://npat-efault.github.io/programming/2016/10/10/escape-analysis-and-interfaces.html
1 | package main |
逃逸分析确认:
1 | go build -gcflags '-m -m -l' 5.go |
性能测试分析:
1 | package main_test |
禁止使用 inline 方式的函数调用性能报告:
1 | # 禁止使用 inline |
启用了 inline 方式的函数调用性能报告:
1 | # 如果启用了 inline,性能差别非常明显 |
关于切片
由于切片一般都是使用在函数传递的场景下,而且切片在 append 的时候可能会涉及到重新分配内存,如果切片在编译期间的大小不能够确认或者大小超出栈的限制,多数情况下都会分配到堆上。
大小验证
1 | package main |
1 | $ go build -gcflags "-m -m" slice_esc.go |
如果 slice 大小超过 64k,则会分配到堆上 (go 1.9.2)
1 | package main |
1 | $ go build -gcflags "-m -m" slice_esc.go |
指针类型切片验证
1 | package main |
1 | $ go build -gcflags "-m -m -l" slice_esc.go |
对于保存在 []*string 中的字符串都会直接在堆上分配。
1 | package main |
1 | $ go build -gcflags "-m -m -l" slice_esc.go |
由于 s := make([]*string, 0, randSize) 大小不能编译确定,所以会逃逸到堆上。
除特别声明本站文章均属原创(翻译内容除外),如需要转载请事先联系,转载需要注明作者原文链接地址。
参考
- Golang 内存逃逸分析
- 深入解析 Go 中 Slice 底层实现 ***
- 以C视角来理解Go内存逃逸
- golang string和[]byte的对比
- Go Slices: usage and internals
- Where is append() implementation?
- SliceTricks ***
- Variadic func changes []byte(s) cap #24972
- spec: clarify that conversions to slices don’t guarantee slice capacity? #24163
- Golang escape analysis ***
- Go Escape Analysis Flaws
- Escape Analysis for Java
- Language Mechanics On Escape Analysis 中文 中文2
- Allocation efficiency in high-performance Go services ***
- Profiling Go Programs
- https://github.com/mushroomsir/blog/blob/master/Go%E4%B8%ADstring%E8%BD%AC%5B%5Dbyte%E7%9A%84%E9%99%B7%E9%98%B1.md
- the-go-programming-language-report
- https://golang.org/doc/faq
- 年终盘点!2017年超有价值的Golang文章
- Golang 垃圾回收剖析
- 深入Golang之垃圾回收