
原文地址:Getting to Go: The Journey of Go’s Garbage Collector 12 July 2018
作者:Richard L. Hudson
翻译:狄卫华
Blog: https://www.do1618.com
这是我在 2018 年 6 月 18 日内存管理国际研讨会(ISMM)上发表的主题演讲稿。过去 25 年来,ISMM 一直是内存管理和垃圾回收论文发表的首选,我很荣幸被邀请发表主题演讲。
翻译备注:
Runtime 运行时,一般不翻译
Latency 延时
The Tail at Scale 规模的长尾效应
Read Barrier 读屏障
摘要
Go 语言的特性、目标和用例迫使我们重新思考整个垃圾回收机制,并将我们带入了一段令人振奋旅程。本文简单描述了这段旅程,这是一个以开源和谷歌的生产需求为动力的旅程,可谓是山穷水尽疑无路柳暗花明又一村。 演讲将深入探讨我们为什么要进行及如何进行这段旅程以及 2018 正在准备的下一段旅程。
个人简介(Bio)
Richard L. Hudson(Rick)以其在内存管理方面的工作而被众人所知,包括 Train,Sapphire 和 Mississippi Delta 算法的发明以及 GC 栈映射,这些映射可用于 Modula-3,Java,C# 和 Go 等静态类型语言垃圾回收 。 Rick 目前是 Google Go 团队的成员,负责解决 Go 的垃圾回收和 Runtime 相关问题。
联系方式:rlh@golang.org
评论:请参阅 golang-dev 上的讨论。
正文

我是 Rick Hudson。
这是关于 Go Runtime,特别是垃圾回收相关的讨论。 我这里有大约 45-50 分钟的材料,之后我会在附近,我们将有时间进行讨论,欢饮随时和我讨论。

在开始之前,我想要感谢一些人。
讨论中的很多材料都是由 Austin Clements 完成的。 感谢 Cambridge Go 团队中 Russ,Than,Cherry 和David。 Cambridge Go 一直是一个充满活力、吸引力的有趣团队。
还要感谢全球 160 万 Go 用户给我们提出的如此有趣的难题。 没有你们,这些难题可能从来不会出现。
最后,我要感谢 Renee French,感谢她多年来一直在制作的所有这些优秀的 Gophers 素材。 在整个演讲中你会看到其中一些。

在进行以下内容之前,我们必须介绍一下 Go 中 GC 看起来如何。

首先,Go 程序有数十万个栈。 它们由 Go 调度程序管理,并始终在 GC 安全点处被抢占。 Go 调度程序将 Go 例程多路复用到 OS 线程上,希望每个 HW 线程运行一个 OS 线程运行。 我们通过复制它们并更新栈中的指针来管理栈及其大小。 这是一个本地操作,因此它具备很好的扩展性。

接下来的重要事实是,Go 是一种基于传统类C语言的面向值的语言,而不是传统中大多数运行时托管的面向引用语言。这决定了 tar 包中的类型如何在内存中布局。所有字段都直接嵌入在读取(Reader)的值中,这使程序员可以在需要时可以更好地控制内存布局。使用具有相关值的字段,这有助于缓存局部性。
面向值也有助于外部功能接口。我们有一个快速的基于 C 和 C++ 的 FFI (Foreign Function Interface) 。显然,Google 拥有大量用 C++ 开发的基础功能。 我们不能期望在 Go 中重新实现这些所有功能,所以 Go 必须通过外部函数接口访问基础功能系统。
这个设计决策决定我们必须做一些的更令人惊奇的事情。最重要的事情可能就是能够将 Go 与其他基于 GC 语言区分开来。
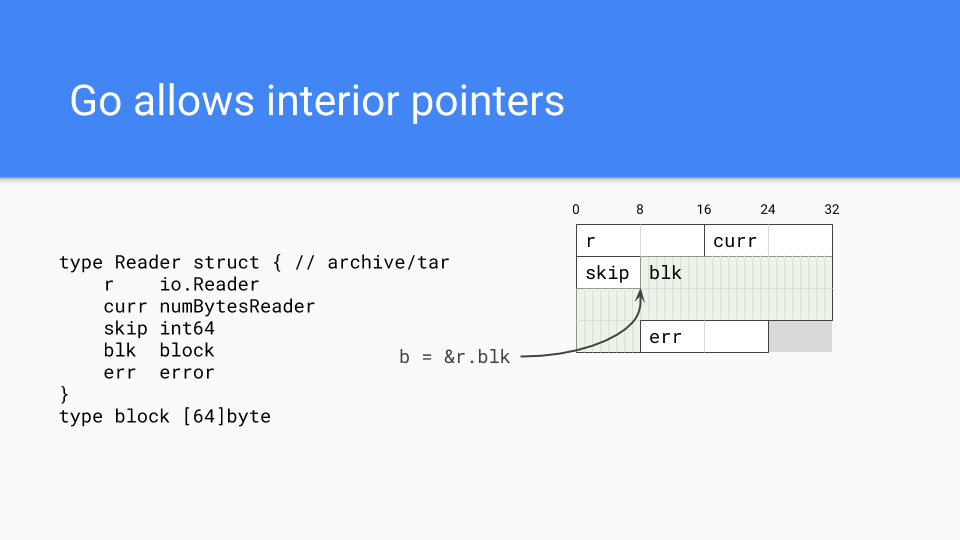
当然 Go 可以有指针,实际上也可以有内部指针。 这些指针保持值存活,并且相当普遍。

我们采用事先编译系统的方法,所以二进制包含整个 Runtime 。 [备注:即所谓的静态编译]
没有 JIT 重新编译,这有利有弊。 首先,程序执行的可重复性要容易得多,这使得编译器改进的速度更快。
备注:JIT (Just-In-Time Compiler) 是一种提高程序运行效率的方法。通常,程序有两种运行方式:静态编译与动态解释。静态编译的程序在执行前全部被翻译为机器码,而解释执行的则是一句一句边运行边翻译。
令人遗憾的是,我们没有机会像使用 JIT 类似系统那样进行反馈优化。
所以有利有弊。

Go 附带两个选项来控制 GC。第一个是 GCPercent。这基本上是一个旋钮,可以调整你想要使用多少 CPU 以及你想要使用多少内存。默认值为100,这意味着一半堆专用于实时内存,一半堆专用于分配。您可以在任一方向修改它。
MaxHeap 尚未对外发布但正在内部使用和评估,它允许程序员设置最大堆值为多少。OOM (OUt of memory) 在 Go 语言中基本不存在;内存使用接近峰值时应该通过增加 CPU 运行来处理,而不是通过中止程序来处理。一般情况下,如果 GC 看到有内存压力,它会通知应用程序适当降低负载。一旦恢复正常,GC 会通知应用程序可以恢复到正常负载。 MaxHeap 还提供了更多的调度灵活性。运行时可以将堆的大小调整为 MaxHeap,而不是总是对有多少可用内存感到担心。
以上包含了我们对 Go 对 GC 重要的部分进行了讨论。

现在,让我们谈谈 Go Runtime 以及我们如何到达这里,以及如何到达我们所处的位置。

在 2014 年,如果 Go不能以某种方式解决这个 GC 延时的问题,那么 Go 就不会成功。 这点非常清楚。
其他新语言也面临同样的问题,Rust 语言采用了不同的方式,但这里我们将讨论 Go 所采用的方式。
延时为何如此重要?

数学在这方面是完全无情的。
隔离 GC 延时服务水平目标 SLO(Service Level Objective)达到 99%,例如 GC 周期 < 10ms 的的时间占比 99% ,简单不能扩展。问题是延迟发生在整个会话期间或一天中多次使用应用程序的过程中。假设一个会话浏览多个网页期间发出 100 个服务器请求,或者发起了 5 个会话,每个会话包含 20 个请求。在这种情况下,只有 37% 的用户在整个会话期间拥有一致的小于 10ms 的体验。
如果你希望 99% 的用户拥有10ms 以下的体验,正如我们所建议的那样,数学表明你真的需要针对 4个9 或99.99% 。
因此,2014年,Jeff Dean 刚刚拿出他的论文 “The Tail at Scale”,进行了深入研究。由于它对谷歌未来产生深远的影响,在谷歌内被广泛阅读。
我们把这个问题称为 9s 的暴政。

那么你如何对抗 9s 的暴政呢?
2014 年我们做了很多事情。
如果你想要 10 个答案,则可以一次多询问几个,然后选择前 10 个,这些是你在搜索时候的答案。 如果请求超过50%,则可以重新发出请求或将请求转发给另一台服务器。 如果 GC 即将运行,将拒绝新请求或将请求转发到另一台服务器,直到 GC 完成为止。诸如此类的方式。
所有这些都是非常聪明的人的解决方法,但是他们没有解决 GC 延时的根本问题。 在谷歌规模下,我们不得不解决根本问题。 为什么?

冗余不能够大规模推广,需要新的服务器机房,需要更高的成本。
我们希望能够彻底解决这个问题,并将其视为改善服务器生态系统的一个机会,并在此过程中拯救了一些濒临灭绝的玉米田,并让一些玉米在 7 月 4 日前有机会达到膝盖高度并最终取得收获。

这是 2014 年的 SLO。 是的,我确实是菜鸟,作为团队的新手,对我来说这是一个新的过程,我不想过度承诺。
此外,关于其他语言的 GC 延时的演示只是简单可怕(Plain Scary)。

最初的计划是做一个无屏障的并发复制 GC。 这是一个长期计划。 读屏障(Barrier)的开销存在很大的不确定性,因此 Go 想规避掉。
备注:Barrier 在并行程序中,Barriers 是一种同步的手段,可被视为一种线程同步原语,如一组线程/进程的 Barrier 可以用来同步该线程/进程组,只有当该线程/进程组中所有线程到达屏障点(可称之为同步点)时,整个程序才得以继续执行。参考 Merry Barrier
但在 2014 年的短期内,我们必须共同行动。 我们必须将所有 Runtime 和编译器转换为 Go,当时它们是用 C 语言编写的。 没有更多的 C 语言代码,就没有长尾的 Bug,因为 C 编码器不理解 GC,但对如何复制字符串有一个很酷的想法。 我们需要快速并专注于延时,但性能影响必须低于编译器提供的优化幅度,所以我们受到了很大的限制。 ( We had basically a year of compiler performance improvements that we could eat up by making the GC concurrent)我们基本上有一年的时间来改进编译器性能,以便我们可以进行并发 GC 。 但前提是我们不能降低 Go 程序的速度,这在 2014 年是达不到的。

所以我们退而求其次,不打算进行复制部分的工作。
于是我们决定采用三色并发算法。 在工作早期,Eliot Moss 和我做过理论证明,表明 Dijkstra 的算法适用于多个应用程序线程。 我们还表明则可以解决 STW 问题,而且已经过证明可以做得到。
我们还关注编译器生成的代码的速度。 如果我们在大多数情况下保持写屏障关闭,则编译器优化将受到最小程度的影响,编译器团队可以快速前进。 2015 年也迫切需要短期成功。
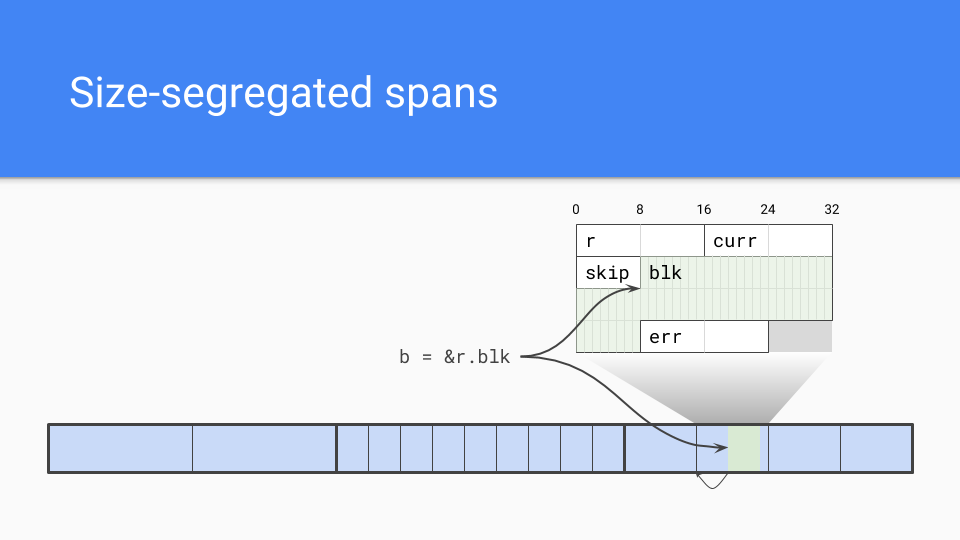
那么让我们来看看做过的部分事情。
我们采取了一个大小隔离的跨度(size segregated span)。内部指针是一个问题。
垃圾回收器需要有效地找到对象的开始。如果它知道跨度中对象的大小,它只需向下舍入到该对象大小,便可以决定对象的开始位置。
当然,尺寸隔离跨度还具有一些其他优点。
低碎片化:根据 C 的经验,除了谷歌的 TCMalloc 和 Hoard 之外,我还与英特尔的Scalable Malloc 密切合作,这项工作让我们相信碎片不会成为非移动分配器(non-moving allocators)的问题。
内部结构:我们完全理解并具有经验。我们了解了如何进行大小隔离跨度,我们了解如何进行低或零竞争的分配方法。
速度:非复制并不是我们关心的重点,诚然分配可能会更慢但仍然是 C 的顺序。谁可能没有凸指针( bump pointer)那么快,但是没关系。
除此之外,我们还有这个外部函数接口问题。如果我们没有移动对象,那么就没有必要处理可能遇到的长尾 Bug问题,如果你有一个移动的回收器,你试图固定对象并在 C 和 Go 对象之间放置间接级别。
备注原文: If we didn’t move our objects then we didn’t have to deal with the long tail of bugs you might encounter if you had a moving collector as you attempt to pin objects and put levels of indirection between C and the Go object you are working with.

下一个设计选择是放置对象元数据的位置。 我们需要对象的一些信息,因为对象没有头部信息。 标记位保留在旁边并用于标记和分配。 每个 Word 中有 2 位与之关联,用于标记它是标量还是指向该 Word 的指针。 它还能指示对象中是否有更多指针,以方便我们尽早停止扫描对象。 我们还有一个额外的位编码,我们可以将其用作额外的标记位或进行其他调试。 这对于运行时发现错误非常有价值。

那么写屏障呢? 写屏障仅在 GC 期间打开。 在其他时候,编译的代码加载一个全局变量并进展检查。 由于 GC 通常是关闭的,因此硬件能够正确地推测写屏障周围分支。 当我们在 GC 内部时,变量是不同的,并且写屏障负责确保在三色操作期间没有可访问的对象丢失。

代码的另一部分是 GC Pacer。这是 Austin 所做的一些伟大的工作。它基本上基于反馈回路,确定何时最佳地启动 GC 回收周期。如果系统处于稳定状态而不是阶段变化,则标记将在内存耗尽时结束。
情况可能并非如此简单,因此 Pacer 还必须监控标记进度并确保分配不会超出并发标记。
如果有必要,Pacer 还会降低分配速度,同时加快标记速度。在高水平上,正在进行大量的分配,Pacer 会停止Goroutine,并将其用于标记。工作量与 Goroutine 的分配成正比。这样可以加快垃圾收集器的速度,同时减慢Mutator 的速度。
完成所有这些工作后,Pacer 将从当前 GC 回收周期中及之前的 GC 回收周期和项目中学习,并决定何时开始下一个 GC 周期。
它做的远不止这些,但这是基本方法。
数学是绝对迷人的,可以从我这里得到设计相关文档。如果你正在做一个并发 GC 你真需要自己看这个数学是否与你的数学相同。如果您有任何建议,请告诉我们。
*Go 1.5 concurrent garbage collector pacing 和 Proposal: Separate soft and hard heap size goal

是的,其中很多部分我们都取得了成功。 一个年轻的疯狂 Rick 会将这些图形并在我的肩膀上纹身,我为他们感到骄傲。
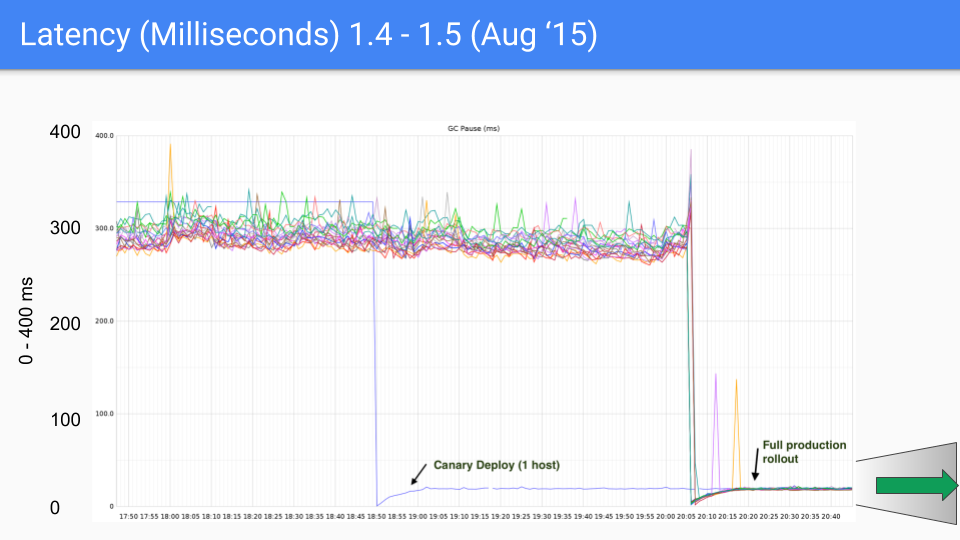
这是在 Twitter 生产服务器上测试的一系列图表。 我们与该生产服务器无关。 Brian Hatfield 完成了这些测量,并在推特上展示了这些。
在 Y 轴上,我们有 GC 延时,以毫秒为单位。 在 X 轴上是相关延时时长,每个点都是在 GC 期间 STW 暂停的时间。
在我们 2015 年 8 月发布的第一个版本中,我们看到从大约 300 到400 毫秒下降到 30 或 40毫秒。 这很好,下降了一个数量级。
我们将在这里将 Y 轴 从 0 到 400毫秒修改成 0 到 50 毫秒。
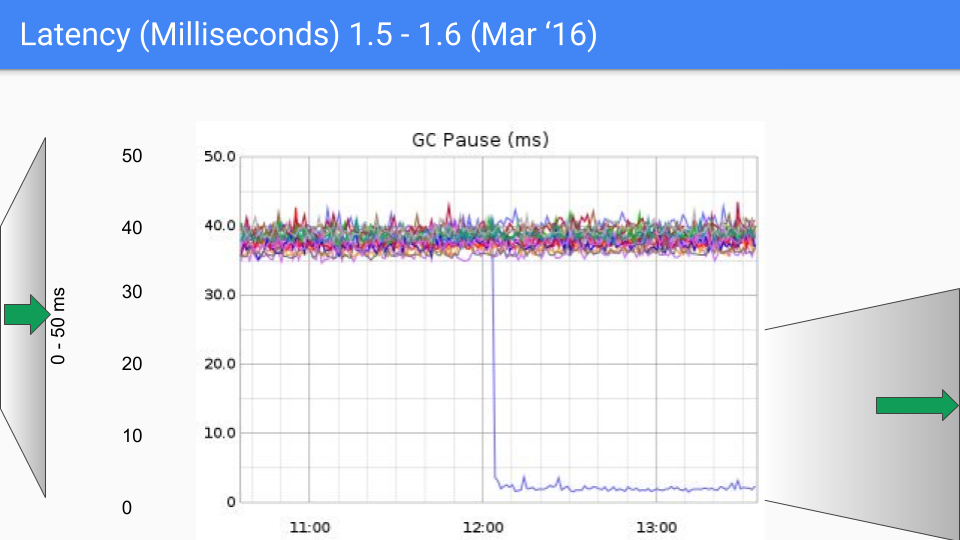
这是 6 个月后。 改进主要是因为系统地消除了我们在 STW 所做的所有 O(heap) 事情。 这是我们的第二个数量级改进,因为我们从 40 毫秒下降到 4或 5 毫秒。
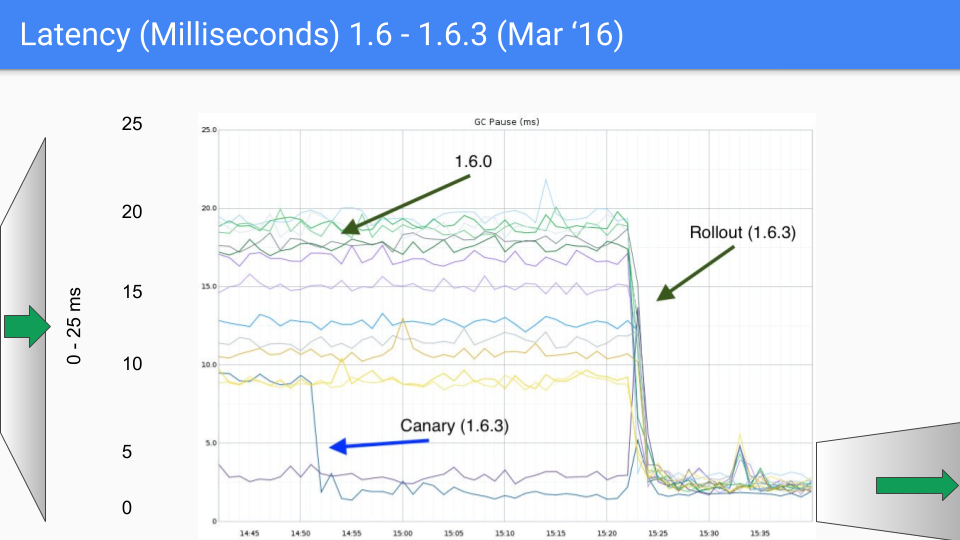
这里有一些我们不得不处理的 Bug,我们在 1.6.3 的小版本中进行了这项工作。 延时降至10毫秒以下,这是我们的 SLO 目标。
我们将再次改变我们的 Y 轴,这次是 0到 5 毫秒。
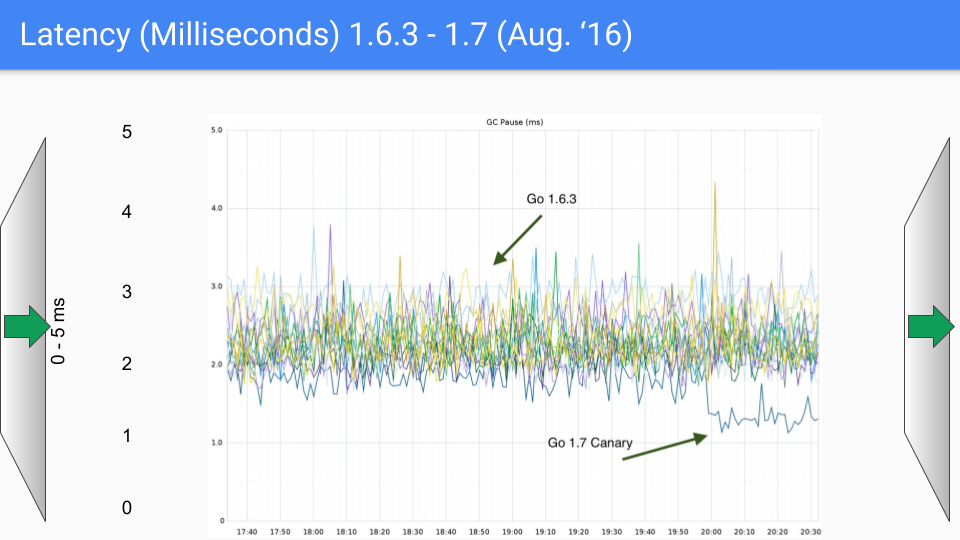
在 2016 年 8 月,距第一次发布正一年。 我们再一次解决了这些 O (heap) 来降低 STW 时间。 我们在这里讨论的是18 Gbyte Heap。 当我们有更大的堆,在我们解决了这些 O(heap) 来降低STW 时间,堆的大小显然可以显著增长,但不再影响延时。 所以这在 1.7 中非常有帮助。
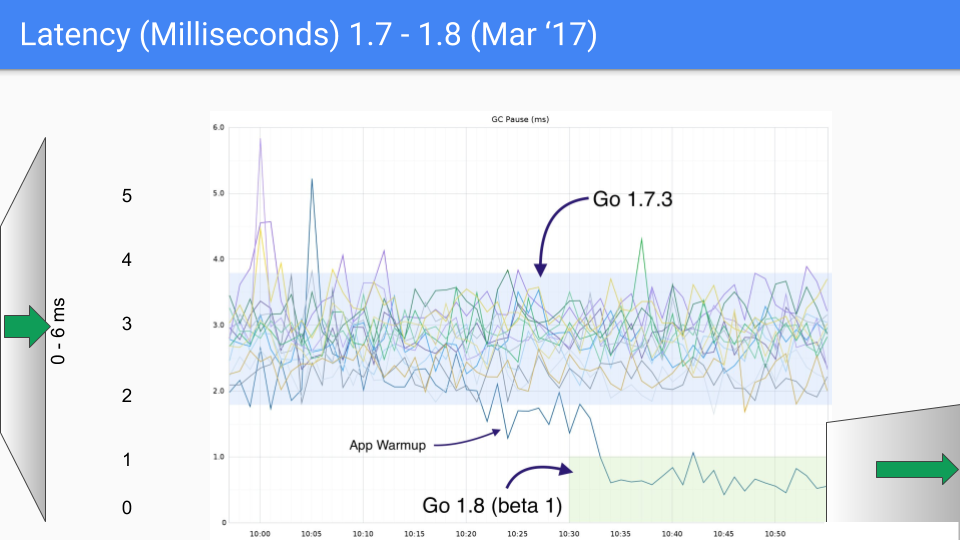
下一个版本发布时间为 2017 年 3 月。我们的最后一次大延时下降是由于弄清楚了如何 GC 清理结束时避免 STW 栈扫描。 这让我们陷入了亚毫秒的范围。 同样,Y 轴即将变为 1.5 毫秒,现在我们有了第三个数量级的改进。
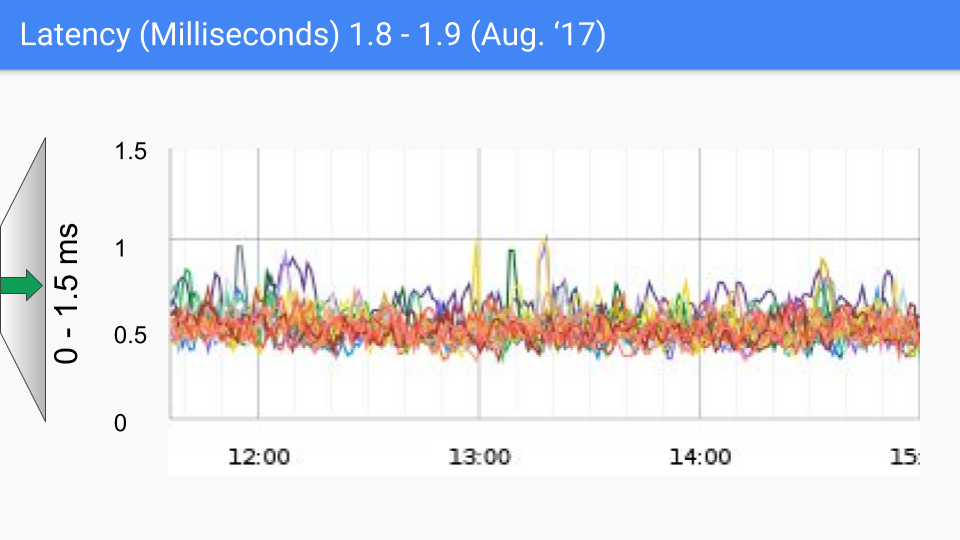
2017 年 8 月的发布版本有比较小的改进。 我们已经知道造成剩余停顿的原因。 这里的 SLO 数值约为 100-200 微秒,我们将持续优化这一点。 如果你看到超过几百微秒的任何东西,那么我们真的想和你谈谈并弄清楚它是否适合我们所知道的东西,或者它是否是我们尚未研究的新东西。 在任何情况下,似乎都没有什么要求降低延迟。 重要的是要注意这些延迟级别可能会因各种非 GC 原因而发生,并且俗话说 “你不必比熊更快,你只需要比你旁边的人快。“
在 2 月 18 日的 1.10 版本中,只进行了一些小的遗留问题清理,并没有实质性的变化。

在 2018 新的一年里,我们设定了了新的 SLO。
我们已将总的 CPU 减少到 GC 循环期间使用的 CPU。
堆仍然是 2 倍。
我们准备将 GC STW 的时间降低到 500 微秒。 也许这里有点激进(Sandbagging ) 。
分配将继续与 GC 辅助成比例。
Pacer 已经变得更好了所以我们期待看到最小的 GC 辅助处于稳定状态。
我们对此非常满意。 同样,这不是 SLA 而是 SLO,所以它是一个目标,而不是一个协议,因为我们无法控制操作系统之类的东西。

以上都是我们的成功经历。 现在让我们谈论失败的经历。 这些是我们的伤疤,有点像纹身,每个人都能得到它们。 无论如何,我们还是讲述一下这些故事。

我们的第一次尝试是做一个叫做面向请求的回收器(Request Oriented Collector)或 ROC。 这个假设可以在这里看到。

这是什么意思呢 ?
Goroutines 是轻量级线程,看起来像 Gophers,所以这里我们有两个 Goroutines。 他们分享一些东西,比如中间的两个蓝色物体。 他们有自己的私有堆栈和自己选择的私有对象。 左边的人想要分享绿色物体。
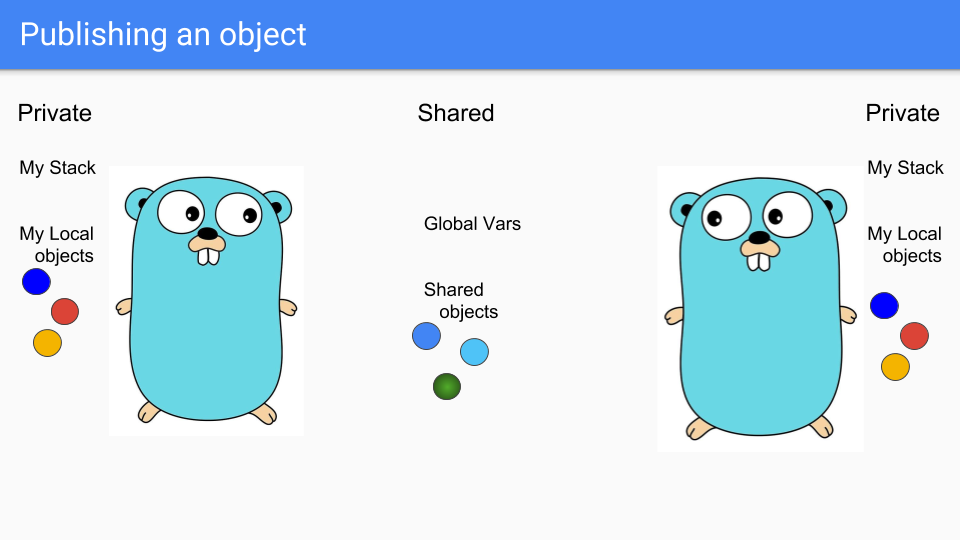
Goroutine 将它放在共享区域,以便其他 Goroutine 可以访问它。 他们可以将它关联到共享堆中的某些内容,或者将其分配给全局变量,另一个 Goroutine 可以看到它。

最后,左边的 Goroutine 走到消亡的阶段,它即将悲伤地死去。
如你所知,它死后不能带走相关的对象和栈。 此时栈实际上是空的,而且对象无法访问,因此您只需回收它们即可。

重要的,这里是所有操作都是本地进行的,不需要任何全局同步。 这种方法与分代 GC 从根本上不同,并且希望我们从不必进行同步所获得的我们期望中的扩展。

这种方法存在的一个问题是写屏障始终打开。 每当有写入时,我们都必须查看它是否正在将指向私有对象的指针写入公共对象。 如果是这样,我们必须公开所指对象,然后对可达对象进行传递步骤,确保它们也是公共的。 这是一个非常昂贵的写屏障,可能导致许多缓存失效。
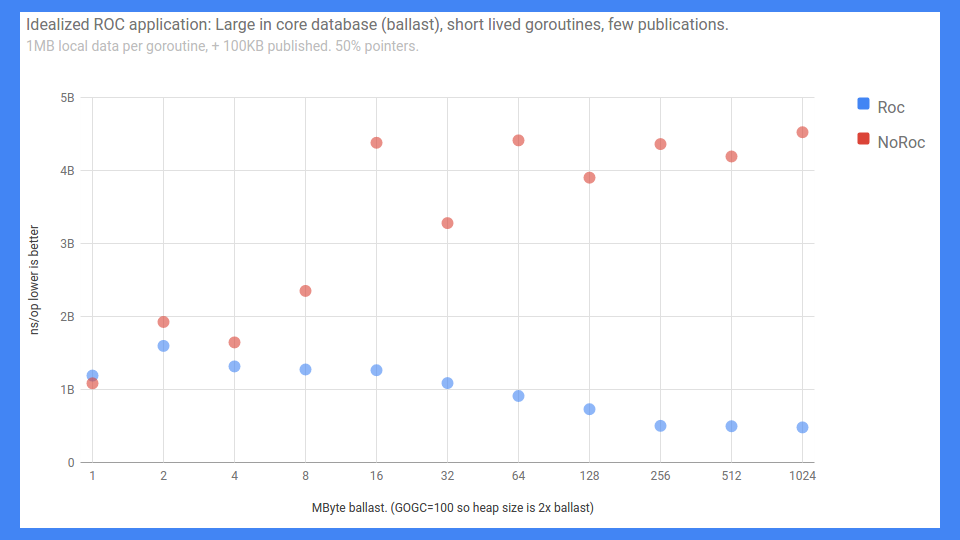
很棒,我们取得了一些相当不错的成功。
这是一个端到端的 RPC 基准测试。 错误标记的 Y 轴从 0 到 5 毫秒(越低越好),无论如何就是这样。 X 轴基本上是负载或核心数据的大小。
备注:The X axis is basically the ballast or how big the in-core database is]。
正如你所看到的,如果你有 ROC 而不是很多共享,那么事情实际上可以很好地扩展。 如果你没有 ROC,那就差不多了。
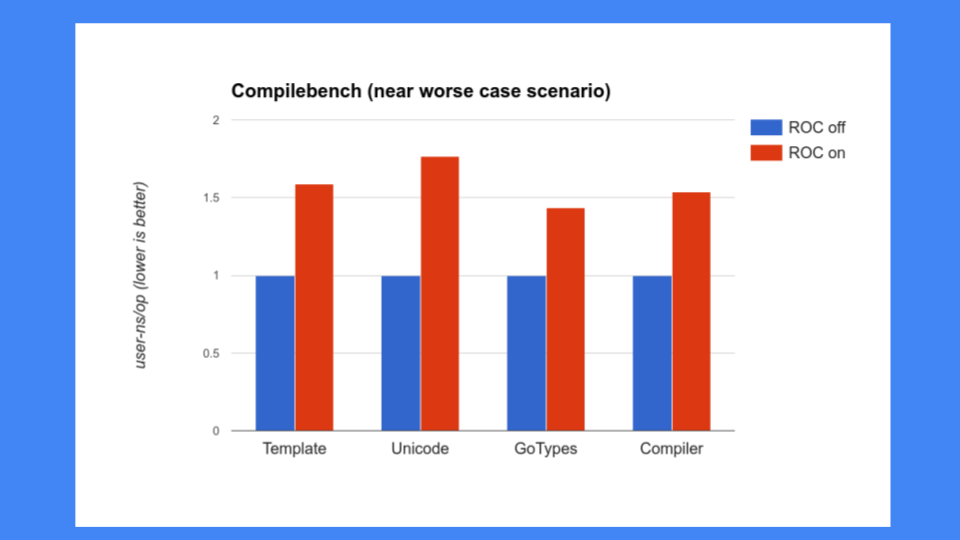
但这还不够好,我们还必须确保 ROC 不会减慢系统的其他部分。 那时我们对编译器有很多担忧,我们无法放慢编译器的速度。 不幸的是,编译器正是 ROC 没有做好的部分, 我们看到 30%,40%,50%和 更多的速度降低,这是不可接受的。 Go 为其编译器的速度感到自豪,因此我们不能放慢编译器的速度,而且也不能降低速度这么多。
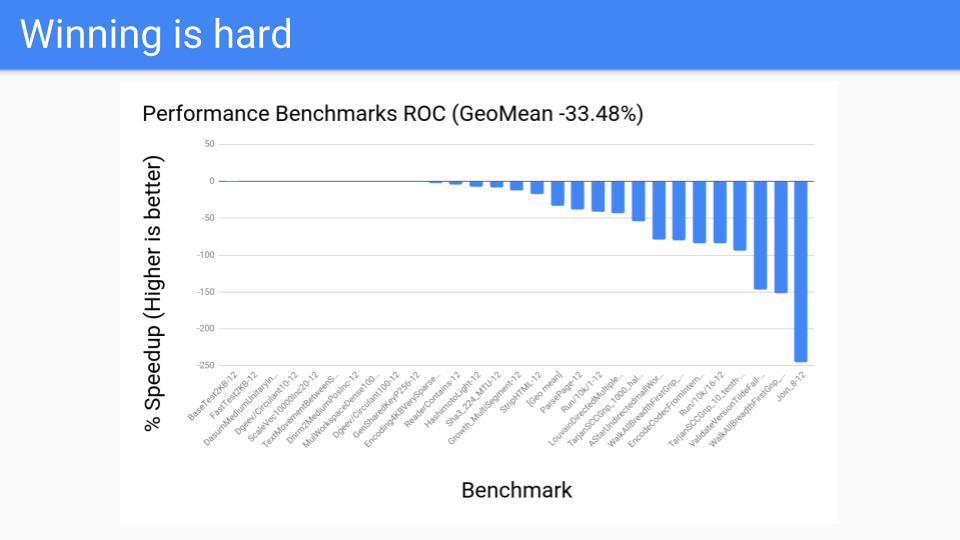
然后我们去看了一些其他程序。 这些是我们的性能基准。 我们有一个200 或 00个基准测试,这些是编译器人员决定对他们工作和改进很重要的基准测试。 这些根本没有被 GC人 员选中。 这些数字一直都很糟糕,ROC 不会成为胜利者。

实际上,我们可以很好的进行扩展,但我们只有 4 到 12 个硬件线程系统,所以我们无法克服写屏障带来的损耗。 也许将来当我们拥有128 Core 系统并且 Go 能够很好利用它们时,ROC 的扩展属性可能是一个胜利。 当发生这种情况时,我们可能会回过头来重温这一点,但是现在 ROC 是一个失败的尝试。

那我们接下来要做什么呢? 我们来试试分代 GC 吧。 这是一个老人,但是一个好东西。 ROC 没有用,所以让我们回到我们有更多经验的东西。

我们不会放弃降低延时的目标,这是一个确定的事实。 所以我们需要一个非移动的的分代 GC。
我们可以这样做吗? 是的,但是使用分代 GC,写屏障始终打开。 当 GC 循环运行时,我们使用相同写屏障,但是当 GC 关闭时,我们使用快速 GC 写屏障来缓冲指针,然后在溢出时将缓冲区刷新到标记表中。
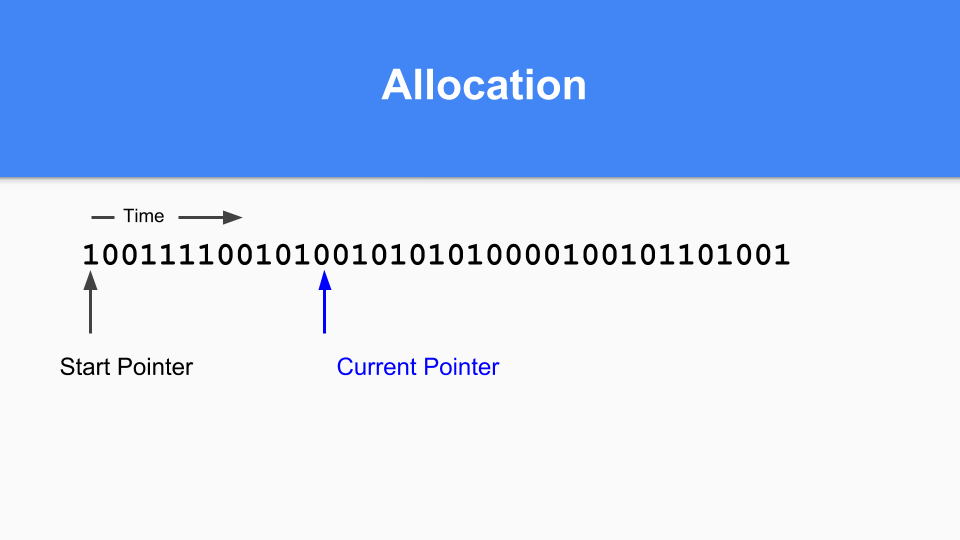
那么这怎么会在非移动的情况下发挥作用呢? 这是标记/分配图。 基本上你维护一个当前指针。 在分配时,查找下一个零值位置,当您发现零时,在该空间中分配一个对象。
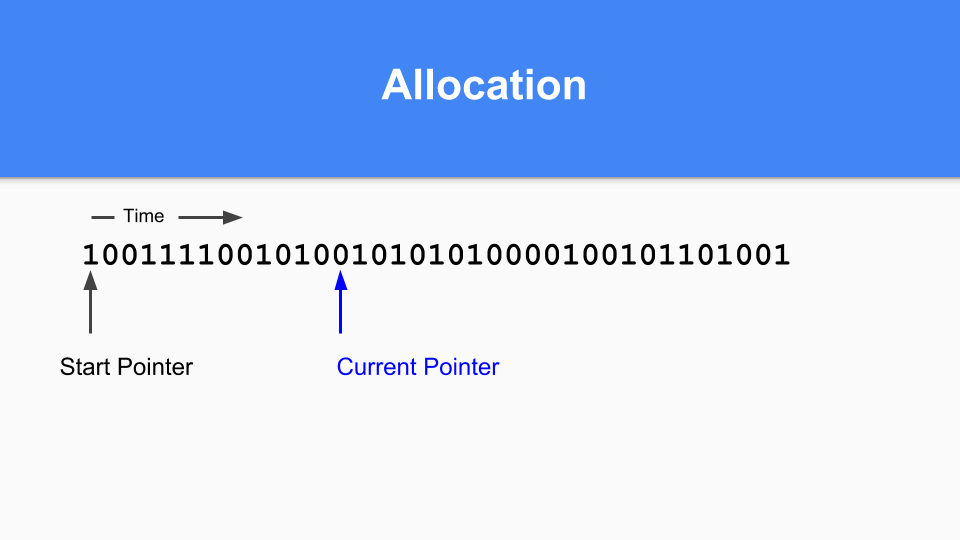
然后,将当前指针更新为下一个 0。
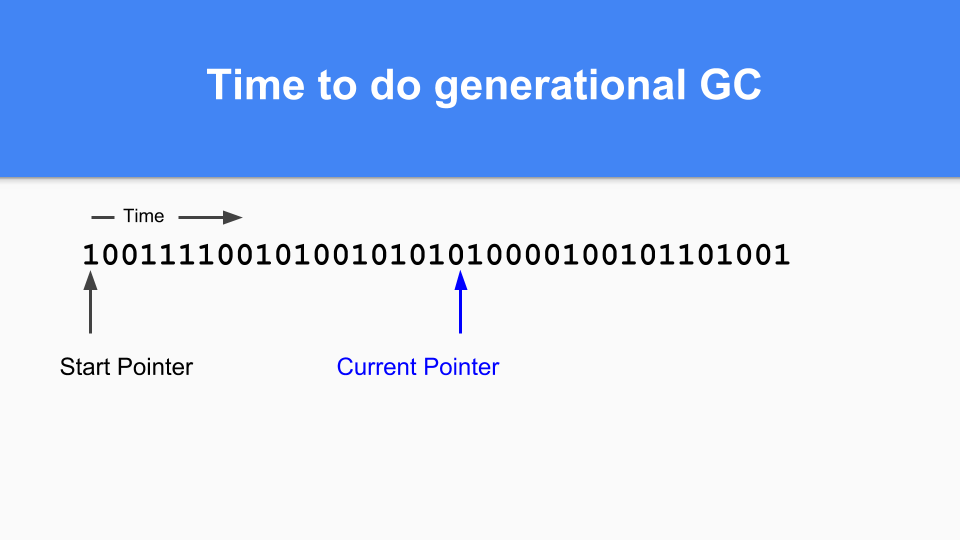
继续,直到某个时候适合进行一次 GC。 您会注意到,如果标记/分配向量中有一个,那么该对象在最后一次 GC 处于活动状态,因此它已经成熟。 如果为零并且你能访问到那么你知道它是年轻的。
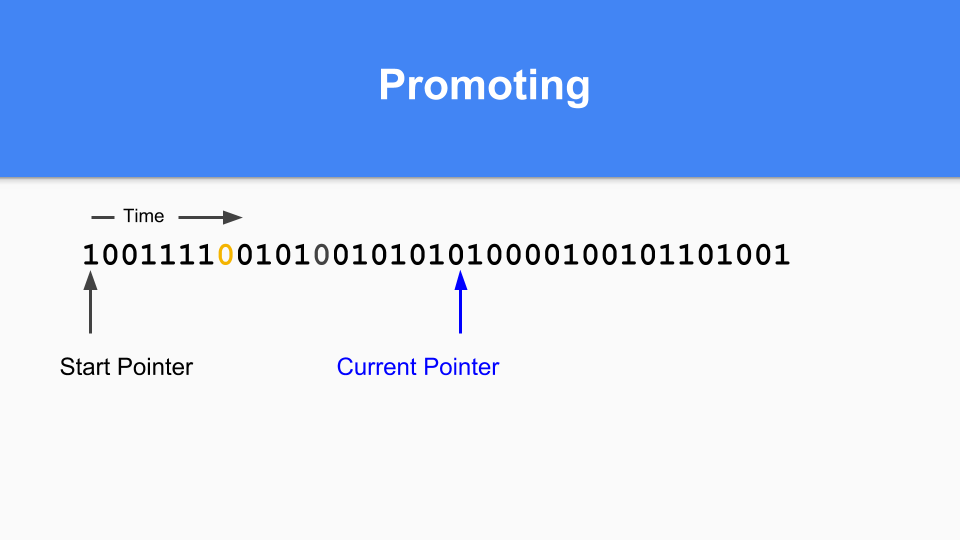
那你怎么做提升(Promoting)。 如果你发现标有 1 的东西指向标有 0 的东西,那么只需将零设置为 1 就可以提升所指对象。
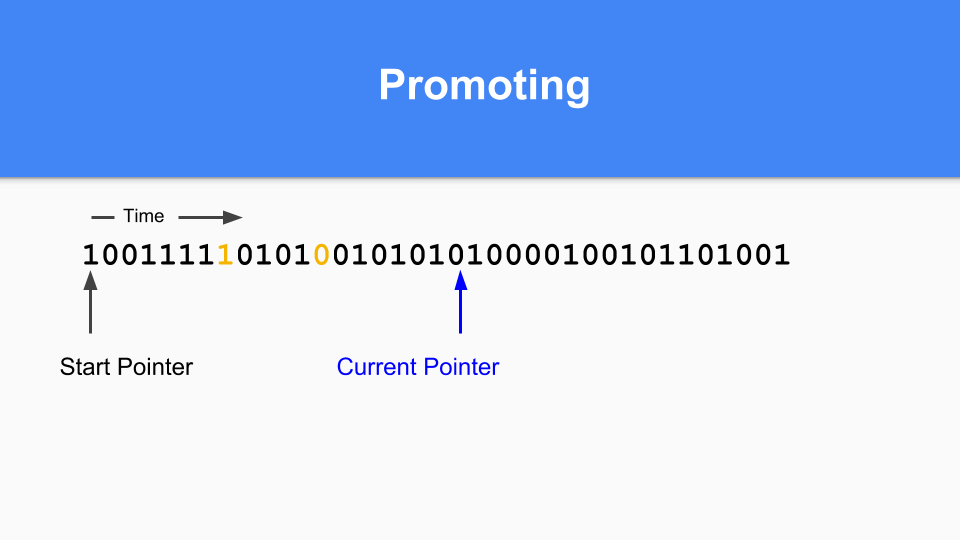
您必须执行转化步骤以确保所有可到达的对象都已得到提升。
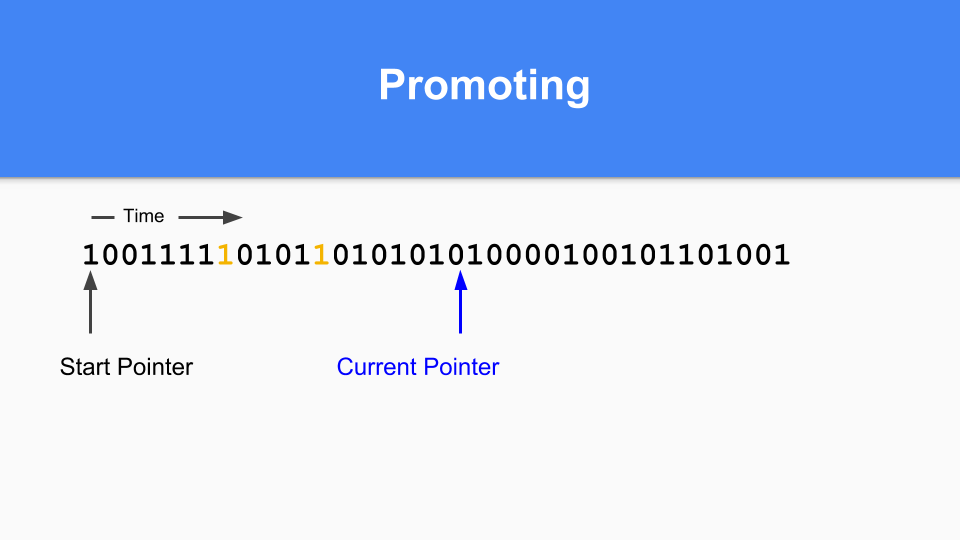
当所有可到达的对象都被提升时,次要 GC 终止。

最后,要完成您的传统 GC 过程,只需将当前指针设置回起始位置即可继续。 在 GC 周期中未到达所有0,因此是免费的并且可以重复使用的。 正如许多人所知,这被称为 “粘性位”,由 Hans Boehm 及其同事发明。
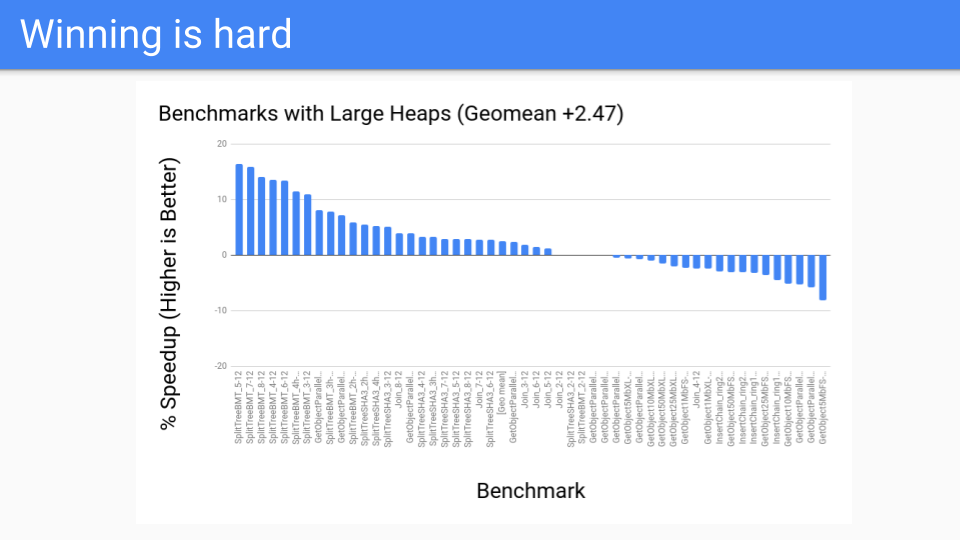
那么性能是什么样的呢? 这对堆比较大的情况来说并不坏。 这些是 GC 应该做得很好的基准。 这一切都很好。
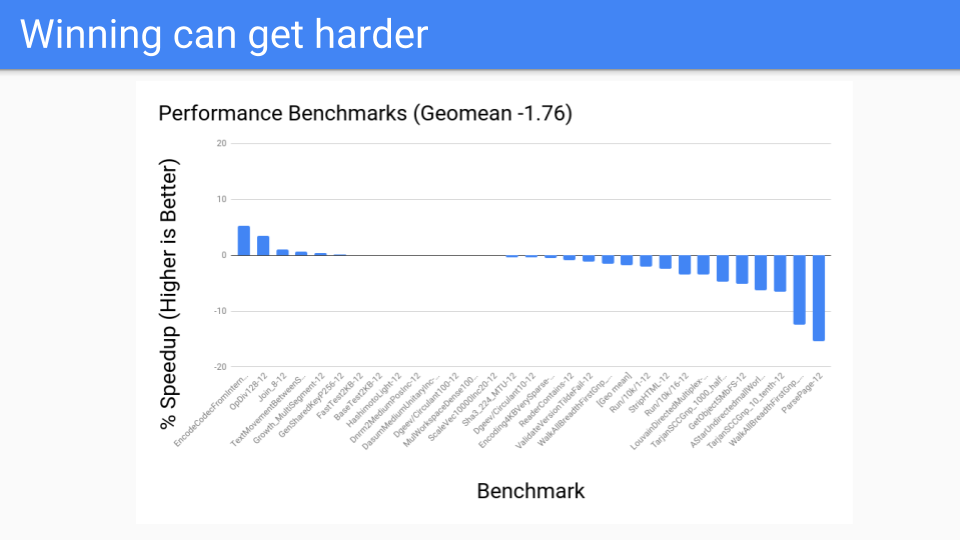
然后我们进行性能基准,事情并不顺利。 那是怎么回事?

写屏障速度很快,但速度不够快。 此外,很难优化。 例如,如果在分配对象和下一个安全点之间存在初始化写入,则可能发生写屏障省略 (Elision)。 但是我们不得不转移到一个系统,我们在每个指令都有一个 GC 安全点,所以我们可以忽略任何写障碍。

我们也进行了逃逸分析,并且越来越好了。 还记得我们谈论面向值的章节吗? 我们将传递实际值,而不是将指针传递给函数。 因为我们传递了一个值,逃逸分析只需要进行过程内逃逸分析而不是过程间分析。
当然,在指向本地对象的指针在转义的情况下,对象将被堆分配。
并不是传统的假设对于 Go 来说并不适用,年轻的物体在栈中生存和死亡。 结果是,分代集合的效率远低于其他托管 Runtime 语言中的有效集合。

所以这些反对写屏障的力量开始聚集起来。 今天,我们的编译器比 2014 年要好得多。逃逸分析正在分析大量这些对象并将它们分配在分代回收期器可能产生帮助的栈对象上。 我们开始创建工具来帮助我们的用户找到逃逸的对象,如果它很小,他们可以更改代码并帮助编译器在栈上分配。
用户越来越聪明地采用以基于值的方法,并且指针的数量正在减少。 数组和映射包含值而不是指向结构的指针。 一切都很好。
但这并不是导致 Go 写障碍向前发展的主要原因。
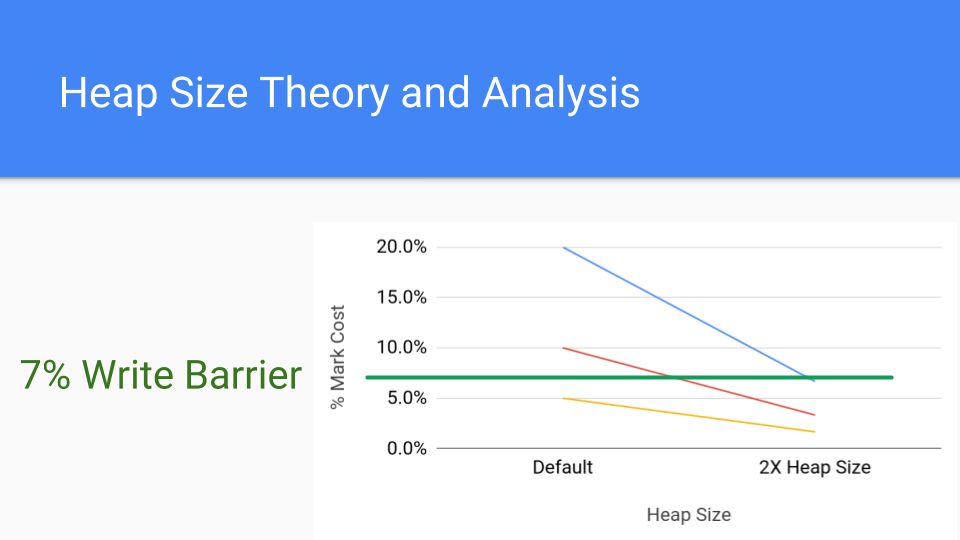
我们来看看这张图。 它只是标记成本的分析图。 每行代表一个可能具有标记成本的不同应用程序。 说你的标记成本是20%,这是相当高的,但它是可能的。 红线是10%,仍然很高。 较低的线是5%,这是近几天的写屏障成本。 那么如果你把堆大小增加一倍会发生什么? 这就是右边的要点。 由于 GC 循环次数较少,标记阶段的累积成本显着下降。 写屏障成本是恒定的,因此增加堆大小的成本将推动标记成本低于写屏障的成本。
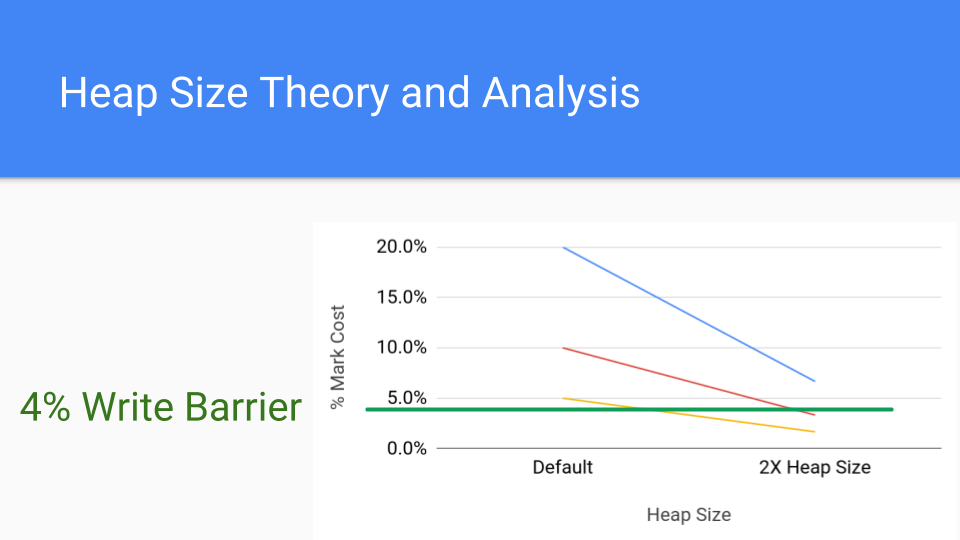
这是写屏障的更常见成本,即 4%,我们发现即使这样,仍然可以通过简单地增加堆大小来降低标记屏障的成本,使其低于写入屏障的成本。
分代 GC 的真正价值在于,当查看 GC 时间时,写屏障成本会被忽略,因为它们会在 Mutator上被抵消 (smeared across the mutator)。 这是分代 GC 的巨大优势,它大大减少了完整 GC 循环的 STW 时间,但并不一定能提高产量。 Go 并没有 STW 这个问题,所以它必须更仔细地看待吞吐量问题,这就是我们所做的。

这是一个很大的失败,而这样的失败来自食物和午餐。 我正在做我惯常的唠叨 “如果不是写障碍,那么 Gee 就不会很棒。” (Gee wouldn’t this be great if it wasn’t for the write barrier.)
与此同时,Austin 刚刚花了一个小时与谷歌的一些硬件 GC 人员交谈,他说我们应该与他们交谈,并试图找出如何获得可能有用的硬件 GC 支持。 然后我开始讲述关于零填充缓存行,可重启原子序列以及其他在我为一家大型硬件公司工作时仅仅听过的方法。 当然,我们在一个名为 Itanium 的芯片中得到了一些东西,但是我们无法将它们带入今天更受欢迎的芯片中。 所以故事的寓意就是使用我们拥有的硬件。
无论如何,让我们谈论一下疯狂的事情怎么样?

没有写屏障的卡片标记怎么样? 事实证明,Austin 有这些方案,他把所有他疯狂的想法写入这些方案中,由于某种原因,他没有告诉我。 我认为这是某种解决的方法。 我曾经和 Eliot 做过同样的事情。 新的想法很容易被打破,人们需要保护它们并在让它们进入这个世界之前使它们变得更强大。 好吧无论如何他把这个想法提了出来了。
这个想法是你在每张卡片中保留成熟指针的哈希值。 如果将指针写入卡中,则散列将更改并且卡将被视为已标记。 这会将写入屏障的成本换成散列成本。

更重要的是它是硬件对齐的。
今天的现代架构有 AES(高级加密标准)指令。 其中一条指令可以进行加密级散列,如果我们也遵循标准加密策略,则加密级散列我们不必担心冲突。 所以散列不会花费太多,但我们必须加载我们要散列的内容。 幸运的是,我们依次遍历内存,因此我们获得了非常好的内存和缓存性能。 如果你有一个 DIMM 并且你点击顺序地址,那么这是一个胜利,因为它们比击中随机地址更快。 硬件预取程序将启动,这也将有所帮助。 无论如何,我们有50年,60 年的设计硬件来运行 Fortran,运行 C,并运行 SPECint 基准测试。 毫不奇怪,结果是硬件快速运行这种东西。
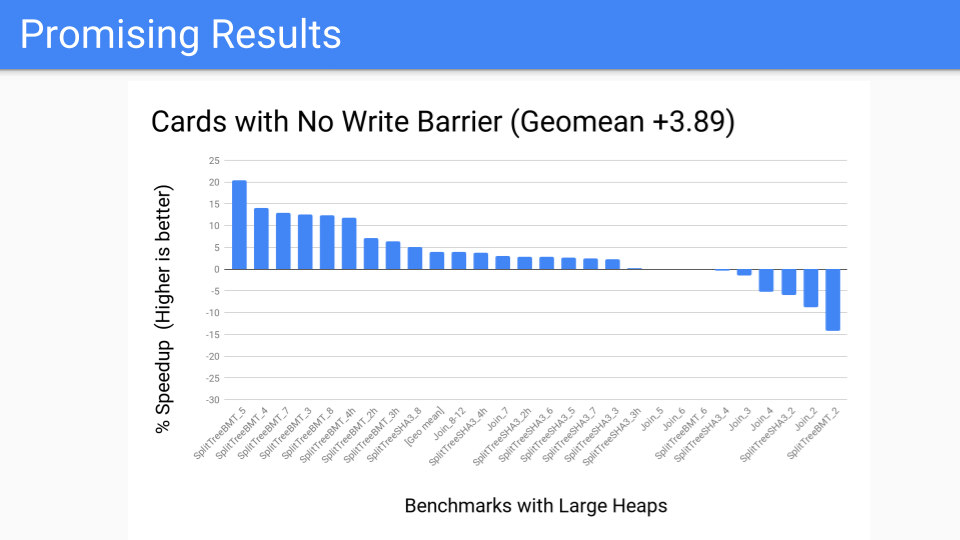
我们进行了测量。 这很不错。 大部分的基准套件应该是好的。
然后我们说了性能基准的样子是什么样的? 不太好,有几个异常值。 但是现在我们已经将写障碍从在 Mutato r中始终打开到作为 GC 循环的一部分运行。 现在,关于我们是否要进行分代 GC 的决定会延迟到 GC 循环的开始。 自从我们对卡工作进行了本地化后,我们就有更多的控制权, 现在我们有了工具,我们可以将它转交给 Pacer,它可以很好地动态切断正确的程序并且不会受益于分代 GC。 但这是否会赢得未来? 我们必须知道或至少考虑未来的硬件状况。

未来的内存是什么样子的?
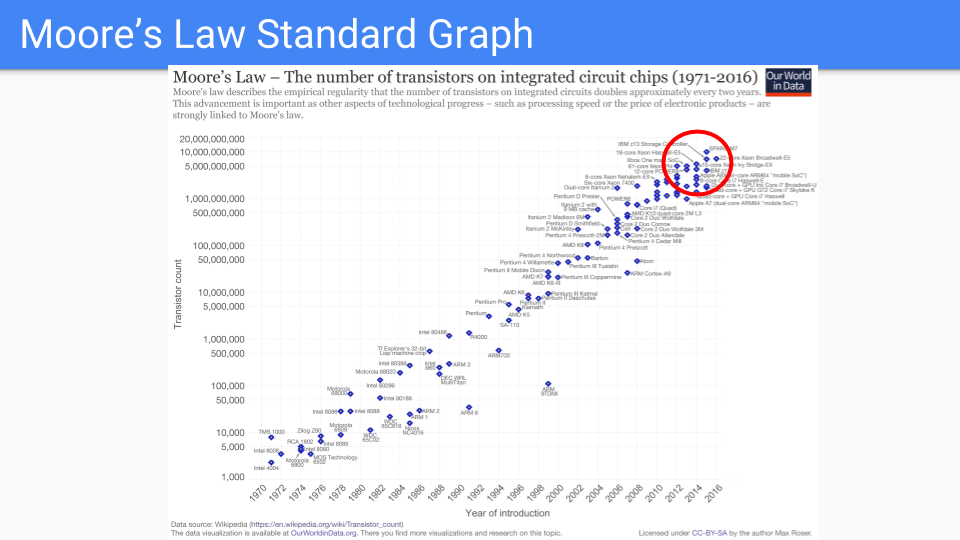
我们来看看这张图。这是您熟悉的经典摩尔定律图。您在 Y 轴上有一个对数刻度,显示单个芯片中的晶体管数量。 X 轴是 1971 年至 2016 年之间的年份。我将注意到,这些年代某人预言摩尔定律已经死亡。
十年前,Dennard 缩放已经结束了频率改进。新流程需要更长时间才能提升。所以不是 2 年,而是 4 年或更长时间。因此很明显,我们正在进入摩尔定律放缓的时代。
让我们看一下红圈中的芯片。这些是维持摩尔定律最好的芯片。
它们是逻辑越来越简单并且重复多次的芯片。许多相同的内核,多个内存控制器和高速缓存,GPU,TPU 等等。
随着我们继续简化和增加重复,我们渐渐地用几根导线,一个晶体管和一个电容器结束。换言之,DRAM 存储器单元。
换句话说,我们认为双倍内存将比双核更好。
原始图表在 www.kurzweilai.net/ask-ray-the-future-of-moores-law。
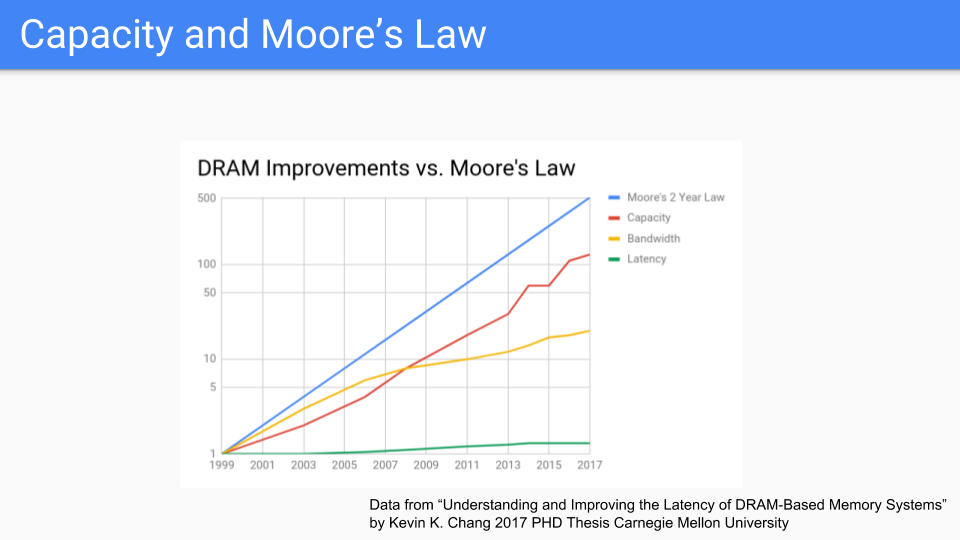
让我们看一下专注于 DRAM 的另一个图。这些是来自 CMU 最近的博士论文的数字。如果我们看一下这个,我们就会发现摩尔定律是蓝线。红线是容量,似乎遵循摩尔定律。奇怪的是,我看到一张图表一直追溯到 1939 年,当时我们使用的是鼓存储器,而且容量和摩尔定律在一起,所以这个图表已经持续了很长时间,肯定比这个房间里的任何人都长一直活着。
如果我们将这个图表与 CPU 频率或各种 Moore-law-is-dead 图表进行比较,我们得出的结论是,内存或至少是芯片容量将遵循摩尔定律比 CPU 更长。带宽(黄线)不仅与存储器的频率有关,而且与芯片可以脱离的引脚数量有关,因此它不能保持良好但不是很糟糕。
虽然我会注意到顺序访问的延迟优于随机访问的延迟,但延迟(绿线)的效果非常差。
(数据来自 “理解和改善基于DRAM的存储系统的延迟,部分满足电气和计算机工程哲学博士学位的要求” Kevin K. Chang,卡内基梅隆大学电气与计算机工程硕士,电子与计算机工程,卡内基梅隆大学卡内基梅隆大学匹兹堡,宾夕法尼亚州2017年5月“。参见Kevin K. Chang的论文。引言中的原始图形不是一种形式,我可以很容易地绘制摩尔定律,所以我将X轴更改为更均匀。)
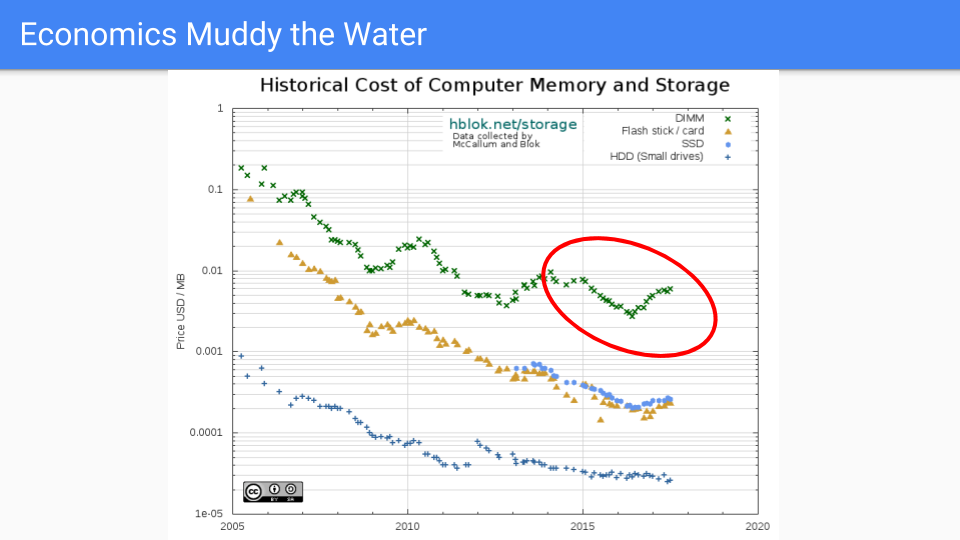
让我们去橡胶与道路相遇的地方。这是实际的 DRAM 定价,它从 2005 年到 2016 年普遍下降。我选择了 2005年,因为那是在 Dennard 缩放结束时以及频率改进的时候。
如果你看一下红圈,这基本上是我们减少 Go 的 GC 延迟的工作时间,我们看到前几年价格表现不错。最近,不太好,因为需求超过供应导致过去两年的价格上涨。当然,晶体管没有变得更大,在某些情况下芯片容量增加,因此这是由市场力量驱动的。 RAMBUS和其他芯片制造商表示,未来我们将看到我们的下一个流程在2019 - 2020年期间缩减。
除了注意到定价是循环的,并且从长期来看,供应有满足需求的趋势,我将不再猜测存储器行业的全球市场力量。
从长远来看,我们认为内存定价将以比CPU定价快得多的速度下降。
(来源https://hblok.net/blog/和https://hblok.net/storage_data/storage_memory_prices_2005-2017-12.png)
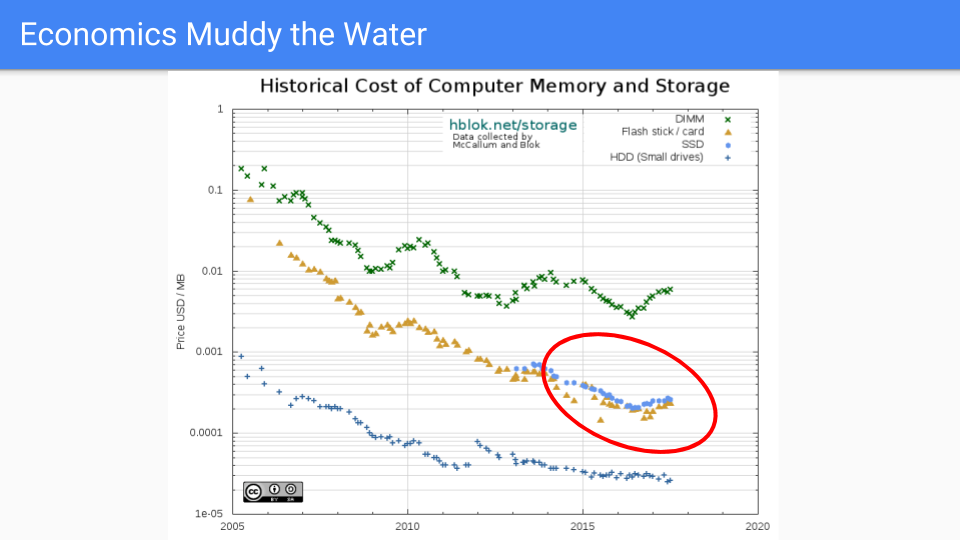
让我们看看另一条线。如果我们在这条线上,那就太好了。这是 SSD 系列。它在保持低价方面做得更好。这些芯片的材料物理特性比 DRAM 要复杂得多。逻辑更复杂,而不是每个单元一个晶体管有六个左右。
展望未来,DRAM 和SSD 之间存在一条界线,其中包括英特尔的3D XPoint和相变存储器(PCM)等NVRAM。在接下来的十年中,这种类型内存的可用性可能会变得更加主流,这只会强化添加内存是为我们的服务器增加价值的廉价方式。
更重要的是,我们可以期待看到DRAM的其他竞争替代品。我不会假装知道哪一个会在五年或十年内受到青睐,但竞争将会激烈,堆内存将更接近突出显示的蓝色SSD线。
所有这些都强化了我们决定避免永远存在的屏障,有利于增加内存。

那么这对 Go 来说意味着什么呢?

当我们查看来自用户的极端情况时,我们打算使 Runtime 更加灵活和健壮。 希望是优化调度程序并获得更好的决定性和公平性,但我们不想牺牲任何性能。
我们也不打算增加 GC API 接口。 我们已经差不多十年了,我们有两个选项,感觉很合适。 没有一个应用程序足以让我们添加新标志。
我们还将研究如何改进我们已经非常好的逃逸分析并优化 Go 的基于值编程。 除了编程以外,还包括我们为用户提供的工具中。
在算法上,我们将关注设计空间的一些部分,以最大限度地减少屏障的使用,特别是那些一直打开的障碍。
最后,也是最重要的是,我们希望摩尔定律能够在接下来的 5 年中肯定地支持 RAM 而不是 CPU,并希望在接下来的十年中。
就是这样了。 谢谢。

附: Go团队希望聘请工程师来帮助开发和维护Go运行时和编译器工具链。
感兴趣吗? 看看我们的空缺职位。
除特别声明本站文章均属原创(翻译内容除外),如需要转载请事先联系,转载需要注明作者原文链接地址。